
File System
This document aims to introduce the types of file systems in QuecPython, their usage, and frequently asked questions, and guide users in using the file system functionality in QuecPython.
Overview
A file system refers to a collection of files and software that manages ad operates the files. It implements storage space management, constructs file structures, and provides access interfaces to operate files. Using a file system allows for easy addition, deletion, retrieval, and modification of files.
Types of File Systems
Currently, various modules use different types of file systems, including EFS, SPIFFS, littleFS, and FATFS.
| File System | Characteristics | Applicable Scenarios | Applicable Models | Open Source URL |
|---|---|---|---|---|
| EFS | Supports various NOR and NAND technologies | Embedded systems with NOR flash, NAND flash, SD cards, EMMC storage | BG95 series module underlying system | Not open |
| SPIFFS | Low resource consumption, balanced erasing, power-off protection | Embedded systems with SPI NOR flash storage | ECx00U&EGx00U&ECx00G series module underlying system | https://github.com/pellepl/spiffs |
| littleFS | Low resource consumption, balanced erasing, power-off protection | Embedded systems with SPI NOR flash storage | All models of QuecPython application layer | https://github.com/littlefs-project/littlefs |
| FATFS | Compatible with Windows FAT32 format | Embedded systems with SD card and EMMC storage | SD card and EMMC storage scenarios for all models | http://elm-chan.org/fsw/ff/00index_e.html |
VFS
Virtual File System. It is an abstract file system built on top of the aforementioned physical file systems. It provides a unified interface to access different physical file systems. The VFS API is compatible with the POSIX standard API. The specific steps for operation are as follows.
Initialize Physical File System
This step mainly involves initializing the storage media hardware, mounting the physical file system, and obtaining the handle and file operation interface of the physical file system. Each physical file system has its own independent hardware initialization and mounting interface. The initialization interface for littleFS is uos.VfsLfs1() (refer to the wiki for specific description), the initialization interface for SPI SD card FATFS is uos.VfsFat() (refer to the wiki for specific description), and the initialization interface for SDIO SD card FATFS is uos.VfsSd() (refer to the wiki for specific description). If the initialization is successful, these interfaces will eventually return objects of the physical file system, which contain information such as the handle and file operation interface of the physical file system.
Mount Virtual File System
This step binds the interface of the physical file system to the interface of the virtual file system. The specific interface is uos.mount(vfs_obj, path). The parameter vfs_obj is the object returned by the initialization of the physical file system in the previous step, and the parameter path is the root directory of the virtual file system. The virtual file system distinguishes different physical file systems based on the root directory, so each physical file system is bound to a different root directory. Depending on the application scenario, the root directory of the file system can be divided into several areas: built-in NOR flash user area /usr, built-in NOR flash backup area /bak, external NOR flash area /ext, SD card area /sd, and EMMC area /emmc. In this way, different storage areas can use the same set of software interfaces by passing different root directories for access.
Unmount Virtual File System
This step unbinds the interface of the physical file system from the interface of the virtual file system. The specific interface is uos.umount(path), where the path is the same as the path passed to the uos.mount() interface.

Applications
Basic File Operations
POSIX API
This function performs basic file operations.
Open a file
open(file, mode="r")file: File path (In QuecPython, user file paths are under '/usr', so all file creation and reading should be done in this directory)
mode: Open mode, optional. It is read-only by default.
| Mode | Description |
| ---- | ------------------------------------------------------------ |
| w | Open the file in write-only mode. If the file exists, it will be opened and edited from the beginning, which means the original content will be deleted. If the file does not exist, a new file will be created. |
| r | Open the file in read-only mode. The file pointer will be placed at the beginning of the file. |
| w+ | Open the file in read-write mode. If the file exists, it will be opened and edited from the beginning, which means the original content will be deleted. If the file does not exist, a new file will be created. |
| r+ | Open the file in read-write mode. The file must exist. The file pointer will be placed at the beginning of the file. |
| wb | Open the binary file in write-only mode. If the file exists, it will be opened and edited from the beginning, which means the original content will be deleted. If the file does not exist, a new file will be created. |
| rb | Open the binary file in read-only mode. The file pointer will be placed at the beginning of the file. |
| wb+ | Open the binary file in read-write mode. If the file exists, it will be opened and edited from the beginning, which means the original content will be deleted. If the file does not exist, a new file will be created. |
| rb+ | Open the binary file in read-write mode. The file must exist. The file pointer will be placed at the beginning of the file. |
| a | Open a file for appending. If the file exists, the file pointer will be placed at the end of the file, and new content will be written after the existing content. If the file does not exist, a new file will be created for writing. |
| a+ | Open a file for reading and writing. If the file exists, the file pointer will be placed at the end of the file, and new content will be written after the existing content. If the file does not exist, a new file will be created for reading and writing. |
| ab | Open a binary file for appending. If the file exists, the file pointer will be placed at the end of the file, and new content will be written after the existing content. If the file does not exist, a new file will be created for writing. |
| ab+ | Open a binary file for reading and writing. If the file exists, the file pointer will be placed at the end of the file, and new content will be written after the existing content. If the file does not exist, a new file will be created for reading and writing. |
Writing to a file
write(str)- str: The data to be written
This method returns the number of bytes successfully written.
Reading from a file
read(size)- size: The data size to read. Unit: byte.
This method returns the data successfully read.
Reading a line from a file
readline(size)- size: The number of bytes to read
This method automatically reads data based on the line ending and returns a string of length equal to size. If size is -1, the entire line will be returned.
Reading all lines from a file
readlines()This method automatically reads data based on the line ending and returns a list containing all the lines.
Moving the file pointer
seek(offset, whence)offset: The starting offset, which represents the number of bytes to move
whence: Optional. It gives offset a definition, indicating where to start the offset. Default value: 0.
0 - starting from the beginning of the file
1 - starting from the current position
2 - means starting from the end of the file
Closing the file
close()This method closes the file and no further operations can be performed on it.
Comprehensive Example
# Create a test.txt file, note that the path is under /usr
f = open("/usr/test.txt", "w+")
i = f.write("hello world\n")
i = i + f.write("hello quecpython\n")
print("Successfully wrote {} bytes".format(i))
f.seek(0)
str = f.read(10)
print("Read 10 bytes: {}".format(str))
f.seek(0)
str = f.readline()
print("Read one line: {}".format(str))
f.seek(0)
str = f.readlines()
print("Read all lines: {}".format(str))
f.close()
# del f # Optional operation, the system will automatically recycle it when gc is executed
print("File closed, test finished")
Running Result
>>> import example
>>> example.exec("/usr/test.py")
Successfully wrote 29 bytes
Read 10 bytes: hello worl
Read one line: hello world
Read all lines: ['hello world\n', 'hello quecpython\n']
File closed, test finished
>>>
When performing operations on directories, etc., the uos library needs to be called for operations. The following is a comprehensive example.
import uos
def main():
# Create a file. No writing operation is performed here
f = open("/usr/uos_test","w")
f.close()
del f
# Check if the file exists
t = uos.listdir("/usr")
print("Checking files in the /usr path: {}".format(t))
if "uos_test" not in t:
print("Newly created file does not exist. Test failed")
return
# Check the file status
a = uos.stat("/usr/uos_test")
print("The file occupies {} bytes".format(a[6]))
# Rename the file
uos.rename("/usr/uos_test", "/usr/uos_test_new")
t = uos.listdir("/usr")
print("The test file is renamed. Check the file in the /usr path: {}".format(t))
if "uos_test_new" not in t:
print("Renamed file does not exist. Test failed")
return
# Delete the file
uos.remove("/usr/uos_test_new")
t = uos.listdir("/usr")
print("The test file is deleted. Check the file in the /usr path: {}".format(t))
if "uos_test_new" in t:
print("File deletion failed. Test failed.")
return
# Direcotry operations
t = uos.getcwd()
print("The current path is:{}".format(t))
uos.chdir("/usr")
t = uos.getcwd()
print("The current path is:{}".format(t))
if "/usr" != t:
print("Fail to change the folder")
return
uos.mkdir("testdir")
t = uos.listdir("/usr")
print("Create the test file folder. Check the file in the current file path:{}".format(t))
if "testdir" not in t:
print("Fail to create the folder")
return
uos.rmdir("testdir")
t = uos.listdir("/usr")
print("Delete the test folder. Check the file in the current file path:{}".format(t))
if "testdir" in t:
print("Fail to delete the test folder")
return
if __name__ == "__main__":
main()
Advanced File Operations
See ql_fs - Advanced Operations of Files.
Backup and Restore
Overview
The software of the QuecPython device consists of firmware and user application scripts. The firmware is stored in the device image partition, while user application scripts are stored in the device file system partition. A file system backup and restore mechanism is designed to ensure system stability. Currently the device has two file system partitions: the user file system /usr and the backup file system /bak. The user file system stores the Python scripts and data files needed for normal operation and is read-write. The backup file system is used to back up the original factory files from the user file system and is read-only. If the backup and restore function is enabled, when files in the user file system are accidentally deleted or modified, the original files will be automatically restored from the backup file system to the user file system. The NOR flash space is distributed as shown in the diagram below:

Implementation Principle
Combine the firmware with the QPYcom tool and check "Backup." The files will be automatically imported into the backup file system partition and two files named checksum.json and backup_restore.json will be generated in the backup file system partition. checksum.json records the CRC checksum values of files in the backup partition. backup_restore.json records the flag indicating whether the backup and restore function is enabled.
During the boot-up phase, if the backup and restore function is enabled, the system will check whether the checksum.json file exists in the user file system partition. If it does not exist, the checksum.json file from the backup file system partition will be copied to the user file system partition. Then, the CRC checksum value from the user file system partition and the CRC checksum value calculated from the user files in the user file system partition are compared. If the file does not exist or the checksum values do not match, the corresponding file from the backup file system partition is copied to the user file system partition, and the CRC checksum value is recalculated and updated in the checksum.json file in the user file system partition.
When user files participating in backup and restore need OTA upgrades, in the last step of the upgrade process, the updated CRC checksum value of the user files is updated in the checksum.json file in the user file system partition.
In summary, the restore action is triggered in the following situations:
- The checksum.json file in the user file system partition is accidentally deleted.
- Data in user file system partition files changes, or files are lost.
Procedures
Select the module.
Select the firmware to be combined.
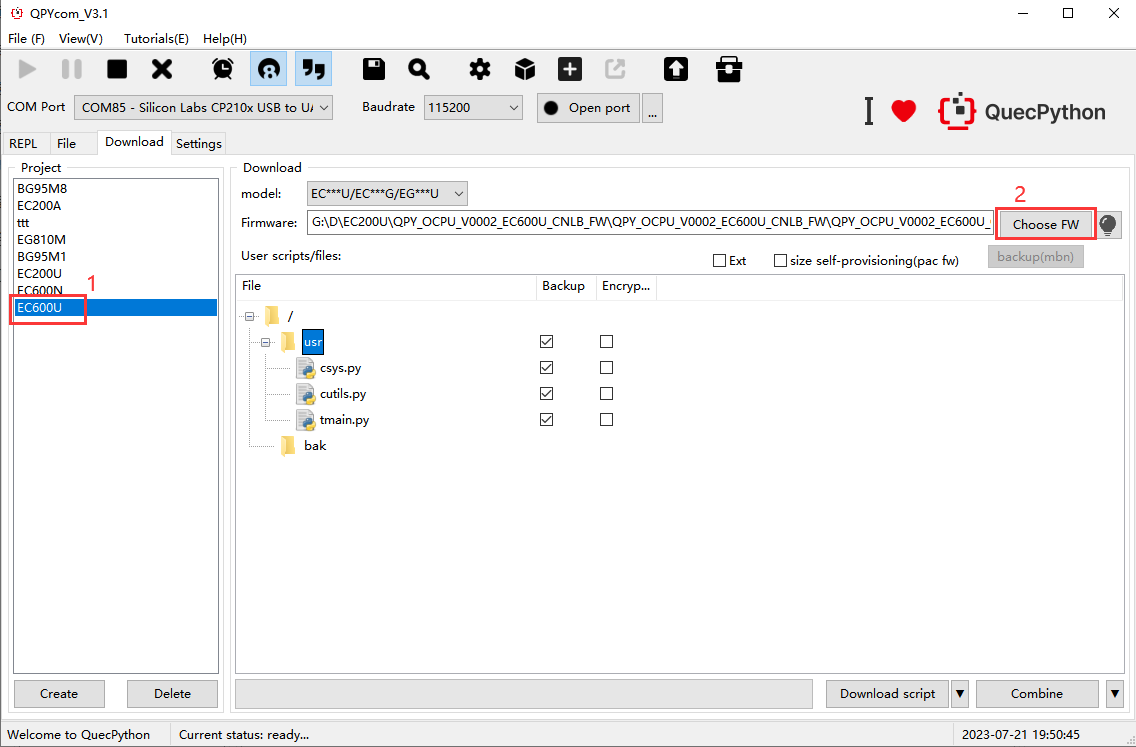
Right click and select usr to pop up the dialog box.
Click "Add file" to add the files to be combined and backed up.
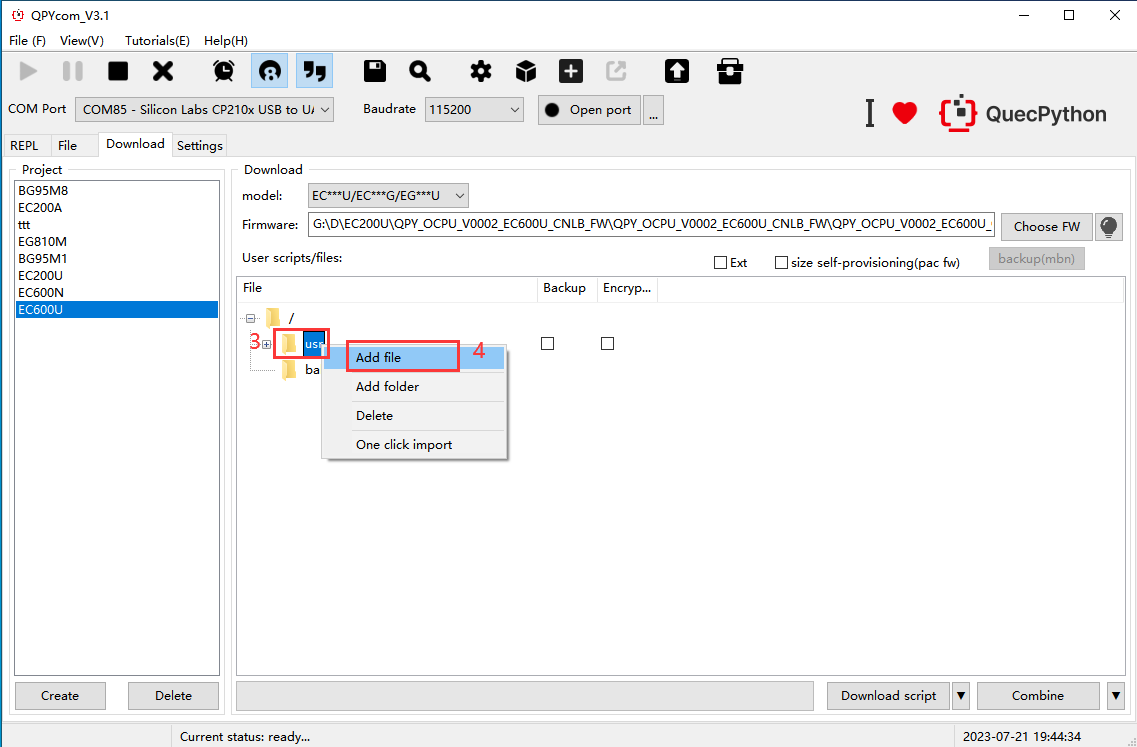
Confirm files added to be combined.
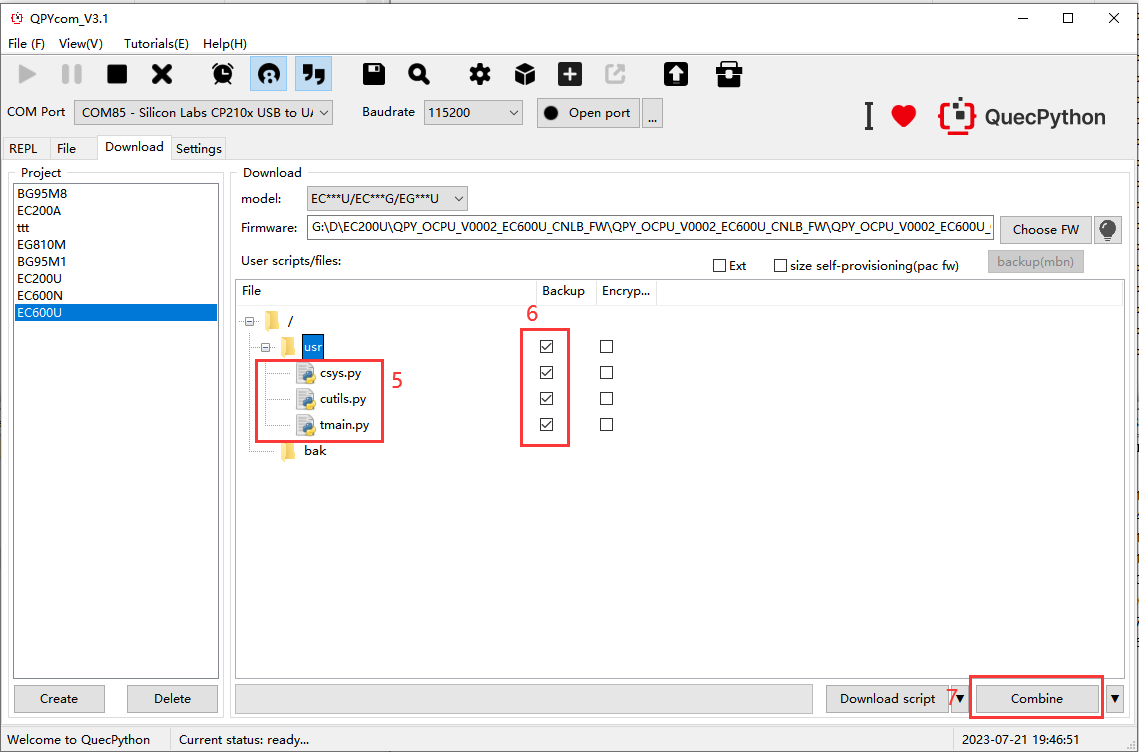
Check the button for backup.
Click the "Combine" button to combine the firmware. After that, firmware with backup and restore functions can be generated.
Matters Needing Attention
Power Failure Protection
To prevent data loss or file system corruption due to sudden power failure during file operations, some file systems are designed to handle random power failures. This means that all file operations have write-on-copy guarantees. If there is a power failure, the file system will recover to the last well state. Both SPIFFS and littleFS support this feature, as mentioned earlier.
Erasing and Writing Leveling
Because the NOR flash storage has a limited erase/write lifespan, it is important to avoid frequent erasing and writing to the same block of memory, as it can lead to that block becoming unusable and affecting the overall usability of the flash storage. Some file systems, such as SPIFFS and LittleFS, have algorithms designed to distribute user erase/write operations across the entire NOR flash storage space.
Read/Write Speed
Read/write speed is primarily determined by the hardware communication interface. For example, SPI 6-wire mode is faster than SPI 4-wire mode, and SDIO 4-wire mode is faster than SPI mode. The method of improving read/write speed: reduce the frequency of open and close operations; open a file once and keep it open until all content has been written before closing it.
In scenarios of SD card, when there are a large number of files stored on an SD card, such as more than 1000 files, frequent open, write, and close operations can be time-consuming. You can reduce the number of files or increase the number of subdirectories and create empty files in each subdirectory in advance to deal with this problem.
For application scenarios that require high real-time performance, use the raw flash interface for access if possible. This is applicable to scenarios such as GUI font files. Additionally, you can employ caching mechanisms to improve access speed by caching frequently accessed data in RAM, so that the data can be read directly from RAM, such as image files used for GUI display.
Space Utilization Efficiency
Due to the limited space of NOR flash storage, efficient space utilization is crucial. Here, we mainly consider the space usage of the NOR flash littleFS file system.
Little File Storage Mechanism:
When a file size is less than or equal to one block (e.g., 4 KB), it consumes a constant block. Even if the file is much smaller than a block (e.g., 1 byte), it still consumes the space of the entire block. This is because LittleFS 1.0 lacks a mechanism to reuse excess block space. However, LittleFS 2.0 introduces an inline file mechanism that stores small files within the space of the containing folder to reduce space consumption.
Large File Storage Mechanism:
When the file size exceeds one block, the mechanism of ctz reverse order linked list is introduced. Compared to the linked list of the traditional file system, this linked list is in reverse order, and there is no additional overhead when appending data to rebuild all the indexes. It also introduces the ctz pointer mechanism, which means if block N is an integer divisible by 2^X, it has a pointer pointing to N - 2^X. The pointer information of large files and the content of the file itself are stored in the same space. When calculating the actual size of the file, the space occupied by the pointers needs to be considered. Therefore, the actual space used by large files is the space occupied by the file itself plus the space consumed by ctz pointers.
Folder Storage Mechanism:
In the littlefs file system, creating a folder requires creating a set of metadata pairs to maintain the contents of this folder, which results in the overhead of two blocks. Therefore, to efficiently use storage space, it is recommended to avoid storing a large number of small files and minimize the use of folders.
Frequently Asked Questions
Mounting Failure
If OSError: [Errno1] EPERM occurs, it is because uos.mount() is called repeatedly.
If OSError: [Errno 19] ENODEV occurs when mounting an external SPI NOR flash, it is usually due to hardware connection issues, such as incorrect SPI port or unreliable hardware connection.
Failed to Create File or Write File
In some models, if a file is not closed before opening it again, it may return a failure. Make sure to open and close files in order.
Even though there is still plenty of space available, an exception error 28 occurs indicating insufficient space when writing a file. If f.seek() is called, it is necessary to ensure that the remaining space is greater than the length from the seek target position to the end of the file due to the file system's power failure protection mechanism.
Difference between with open and open
open is a built-in function in Python. with open is the open function used with the with statement. After using open(), it is necessary to call the close() method to close the file. This is because the file object occupies system resources, and there is a limit to the number of files that can be opened at the same time. Additionally, not using them in pairs may cause other exceptions. Since IO exceptions may occur during file read/write operations, if an error occurs, the subsequent close() will not be called. However, with open can avoid this situation. Even if an IO exception occurs during file read/write operations, the close() method will be automatically called to close the file.
with open('/usr/test.txt','w+') as f:
f.write('1234567890')