
异常处理
内核异常
概述
异常的概念
处理器正常的执行流程一般运行在用户模式中,此时CPU 随程序寄存器内递增的地址,依次取指令并运行,这个过程会不断循环,直到程序执行结束。异常指的是处理器在正常执行程序的过程中,遇到了硬件错误、指令执行错误、用户程序请求服务、内存访问异常、取指令异常等特殊事件,无法继续正常的运行流程,需要立即处理前述特殊事件的过程。
CPU的工作模式
| 处理器工作模式 | 特权模式 | 异常模式 | 说明 |
|---|---|---|---|
| 用户(user)模式 | 用户程序运行模式 | ||
| 系统(system)模式 | 该组模式下可以任意访问系统资源 | 运行特权级的操作系统任务 | |
| 一般中断(IRQ)模式 | 通常由系统异常状态切换进该组模式 | 普通中断模式 | |
| 快速中断(FIQ)模式 | 快速中断模式 | ||
| 管理(supervisor)模式 | 提供操作系统使用的一种保护模式,swi命令状态 | ||
| 中止(abort)模式 | 虚拟内存管理和内存数据访问保护 | ||
| 未定义指令终止(undefined)模式 | 支持通过软件仿真硬件的协处理 |
异常源的分类
异常源大致有如下几种,这里需要和工作模式区分开,异常源是终止CPU正常运行的原因,工作模式则是CPU当前的工作状态。
IRQ(中断):
外部中断请求引脚被触发,一般是外部硬件产生的。
FIQ(快速中断):
快速中断请求引脚有效,一般是外部硬件产生的,相比于IRQ有更快的速度和更高的优先级。
对于当下的ARM M3核,已经不再区分IRQ和FIQ,以M3内核为例,代之以NVIC中断管理体系,每个IRQ都有可编程的优先级,FIQ的作用被最高优先级的IRQ代替。
SWI(软中断):
一种模拟硬件中断的指令,可通过软件方式使CPU进入中断环境,并跳转到指定的执行地址。如软件看门狗的狗咬,以及断言(ASSERT)都可以通过此方式立即获得执行并处理CoreDump。
对于当下的ARM M3核,使用SVC(系统服务调用)来描述这一异常。它们虽然有着不同的实现机制,但是实现的功能是一样的。
RESET(复位):
复位指令,立即使CPU的执行地址指向复位向量,代码从复位向量开始重新运行,一般用于复位。
可由硬件RESET引脚下拉产生,或代码中将PC指向复位向量(软复位)。
Prefetch Abort(指令预取终止):
程序存储器无法正常访问,一般出现野指针、内存踩踏、取指令时访问未申请或已释放的内存空间导致,出现这种异常时,可以选择进行coredump。
Data Abort(数据终止):
数据存储器无法正常访问,一般出现野指针、内存踩踏、取数据时访问未申请或已释放的内存空间导致,出现这种异常时,可以选择进行coredump。
对于当下的ARM M3核,这两种异常被称为总线故障(busfault)。
未定义的指令(UDEF):
当CPU认为当前指令未定义时,会产生未定义的指令异常中断,出现这种异常时,可以选择进行coredump。
对于当下的ARM M3核,未定义指令异常被称为用法故障(usagefault)。
对于当下的ARM M3核,以上异常被除能(例如被屏蔽或CPU处于不可响应异常的操作状态)时,均会产生上访(escalation),触发一种更高优先级的异常——硬故障(hardfault)
这些异常有些是可以通过软件机制解决或恢复(如FIQ和IRQ),此时内核可在处理完异常后恢复异常前的上下文并继续运行,并不影响模组整体的工作状态。
但软件机制并不能解决或恢复所有的异常,当内核出现无法恢复的异常时,我们一般在异常处理程序中应用以下两种处理方式:
- Reset:当出现软件无法恢复的异常时,直接跳转到RESET中断,从而使模组复位,重新开始执行业务。
- 进入dump模式,这种模式会将内核出现异常时的现场保存并输出。
RESET一般用于批量量产,确保设备即使遇到不可恢复的异常,也能重启并恢复正常工作。dump模式一般用于调试阶段,可用于抓取异常信息并分析解决异常。
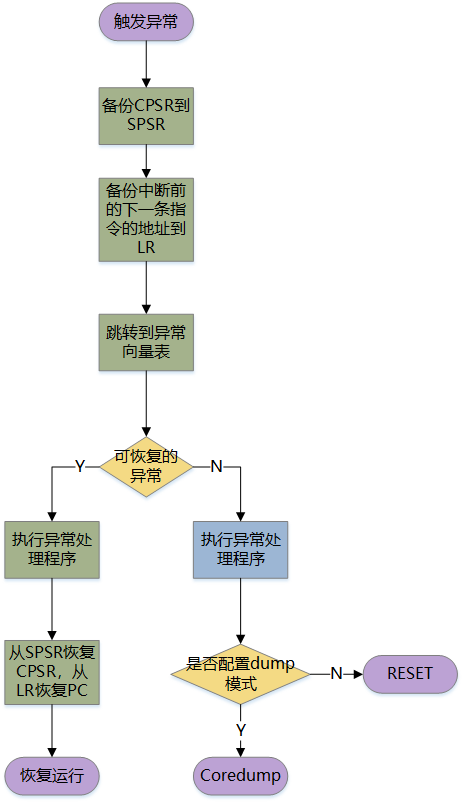
异常响应流程
当异常发生的时候,CPU会停下当前任务,跳转去执行异常处理程序,但是在跳转之前,需要做一些准备工作,比如保存中断之前的工作模式和运算状态、中断位置的下一条指令的地址。
1、CPSR寄存器内容备份
拷贝CPSR寄存器中的内容到对应异常模式下的SPSR寄存器。
正常运行时,CPU是处在用户模式下,现在异常产生了,CPU会进入到对应的异常模式,但是异常模式和用户模式共用CPSR寄存器,所以只能将用户模式下的寄存器数据暂存到 SPSR中。
2、修改CPSR的值
用户模式的数据暂存完毕后,CPSR可以被异常模式使用了,主要完成的工作有如下三个:
修改模式位为对应的异常模式。
修改中断禁止位,禁止相应的中断。
修改状态位进入ARM状态(M3内核一直运行在Thumb状态下,无需切换)。
(1) 修改模式
拿到CPSR寄存器后,首先将工作模式改成相应的异常模式。
(2) 修改中断禁止位
这里禁止相应中断的目的是,CPU在处理当前中断的时候,不希望被其他同优先级的中断打断(除非中断优先级更高)。这里以IRQ异常(优先级较低)和FIQ异常(优先级较高)来举例:
如果发生的是IRQ异常,其他IRQ中断发生时,CPU不会产生响应;FIQ中断发生时,先停下当前的中断处理任务,先去处理FIQ中断,处理完FIQ中断再跳转回来处理IRQ中断。
如果发生的是FIQ异常,那么该异常的处理过程无法被打断,因为不存在更高优先级的中断,同优先级的FIQ中断已经被禁用了。
(3) 修改状态位
如果当前处理器的状态是Thumb状态,这时就需要修改状态位为ARM状态。M3内核只支持Thumb,故不存在改切换过程。
3、保存返回地址
后面异常处理完毕以后,处理器要回到中断的下一个位置继续运行程序,这里我们就需要事先保存中断位置的下一条指令的地址到当前模式的LR。
每一种工作模式有着自己的LR寄存器,如果发生的是IRQ异常,那么就会保存到 r14_irq 寄存器。如果发生的是abort,就会保存到r14_abt寄存器。
4、跳转到异常向量表
异常模式的对应的异常处理程序一般交给用户自行编写,不同异常的对应的处理程序也是不一样的,在进入异常时,并不能直接拿到异常处理程序的入口地址,所以先跳转到异常向量表。
异常向量表在内存中占据32个字节,每个异常源都分配了4个字节的存储空间,这4个字节存放的就是跳转指令,用来直接跳转到异常处理程序的入口位置。
5、执行异常处理程序
跳转到异常处理程序之后,就可以运行我们自定义的异常处理流程了。进行dump或者reset的流程就是在异常处理程序配置的。
6、异常处理完毕的返回动作
(1) 恢复之前的状态
SPSR备份了中断之前的工作模式和运行状态,所以需要将SPSR的值复制给CPSR使处理器恢复之前的状态。
(2) 回到之前中断的下一个位置
在跳转之前,LR保存了中断处的下一条指令的地址,所以需要将LR的值复制给PC使程序跳转回被打断的地址继续执行。
dump以及触发原理
对Quecpython模组而言,Dump是一种特殊的异常处理程序,一般配置在不可恢复的异常中。其作用是保存异常现场的CPU和内存数据,并且以指定方式输出。进入这种模式一般需要满足两个条件:其一,模组CPU产生了无法恢复的异常。其二,模组使能了dump模式。
Dump时,一般做以下操作:
1.拷贝异常现场寄存器值,其中通用寄存器R0-R12、链接寄存器LR指针以及程序计数器PC指针能够还原大多数现场。
2.根据我们配置的模式,建立保存dump信息的通道,一般包括:
从USB/UART输出(此时需要初始化通信协议,例如Ymodem等。部分平台会重新枚举USB口。)
保存到存储介质(初始化对应的存储介质,并检查空间是否满足dump文件之需。)
从JTAG口输出(初始化JTAG硬件。)
鉴于存储空间和使用便捷性,我们一般使用USB或UART来输出dump文件。
3.保存dump文件
将拷贝出来的寄存器和RAM内的信息按照地址进行发送或保存。这种动作称之为”内存转储“。在拿到RAM信息后,我们就能重建异常现场的栈结构、栈帧、堆内存和CPU寄存器等运行状态,从而分析问题所在。
常见的不可恢复异常触发原理一般包括以下几种:
硬件看门狗超时: 硬件看门狗一般连接到CPU的IO引脚,因此可以触发CPU的硬件中断。在产生超时的情况下,看门狗触发CPU中断。中断ISR中通过主动assert等手段触发异常,如果此时使能了dump模式,就会进入dump模式并输出调试信息。
内存踩踏: 出现内存踩踏时,内存里的有效值会被清除或篡改,往往会造成CPU在获取指令或数据时取得非法值。这种情况下的异常主要有两种可能:其一,CPU取到了非法地址并尝试访问,就会造成程序或数据存储器访问失败,触发Prefetch Abort或者Data Abort;其二,有时CPU会根据错误地址跳转到错误的程序入口,造成逻辑异常,进入死循环,引发看门狗超时。当发生以上异常时,如果此时使能了dump模式,就会进入dump模式并输出调试信息。
空指针: 无论对于程序还是数据,空指针都是无效的。一般来说,在使用指针时,代码内需要过滤空指针。如果空指针被装载到了CPU中并执行访问,就会触发Prefetch Abort或者Data Abort。
死循环: 进入死循环时,CPU会被该循环占满,其它任务无法得到正常执行。最终导致看门狗超时触发异常。
assert: 断言,一种调试手段,当输入为FALSE时,主动触发异常,如使用abort或while(1)等。如果使能了dump模式,最终会进入dump模式并输出调试信息。
以上即为dump模式的触发原理。进入dump模式后,模组会保存异常触发时的内存和寄存器信息并输出。后续章节,我们将介绍如何抓取dump调试信息并进行分析。
抓取dump调试信息
在调试过程中如果发生程序异常,我们可以配置模组进入dump模式并抓取调试信息。
如何配置dump模式
一般来说,模组在程序异常时默认的行为是reset,我们需要通过调整NV参数来配置模组异常时进入dump模式,此更改需要从AT口(一般支持主串口和Quectel USB AT Port)下发AT指令来配置,各平台指令如下:
ECX00U/ECX00G(该配置掉电不保存):
at+qdbgcfg="dumpcfg",0
ECX00A/ECX00N/ECX00M(该配置掉电不保存):
AT+LOG=19,1
AT+qdumpcfg=0,0
AT+qdumpcfg=2,1
ECX00E(该配置掉电保存):
AT+ECPCFG="faultAction",0
BG95/BG600L(该配置掉电保存):
AT+QCFGEXT="dump",1
发送以上指令后,模组程序异常后就会进入dump模式而非直接重启。如果需要清除以上配置,恢复reset行为,各平台指令如下:
ECX00U/ECX00G(该配置掉电不保存):
at+qdbgcfg="dumpcfg",1
ECX00A/ECX00N/ECX00M(该配置掉电不保存):
AT+qdumpcfg=0,1
ECX00E(该配置掉电保存):
AT+ECPCFG="faultAction",4
BG95/BG600L(该配置掉电保存):
AT+QCFGEXT="dump",0
除以上指令外,ECX00A/ECX00N/ECX00M平台可以通过清除NV参数来达到恢复reset行为的目的:
AT+RSTSET
如何使用dump工具并抓取dump信息
ECX00U系列模组
ECX00U使用的dump抓取工具与日志抓取工具一致,均为cooltools。如同抓取日志一样,我们通过Quectel USB AP Log Port将模组连接到日志工具。


然后在Plugins菜单下拉框中选择“Activate Tracer”启动Trace tool插件,并点击Tracer工具栏上的绿色箭头,如果有日志输出,则说明模组已经和日志工具连接成功
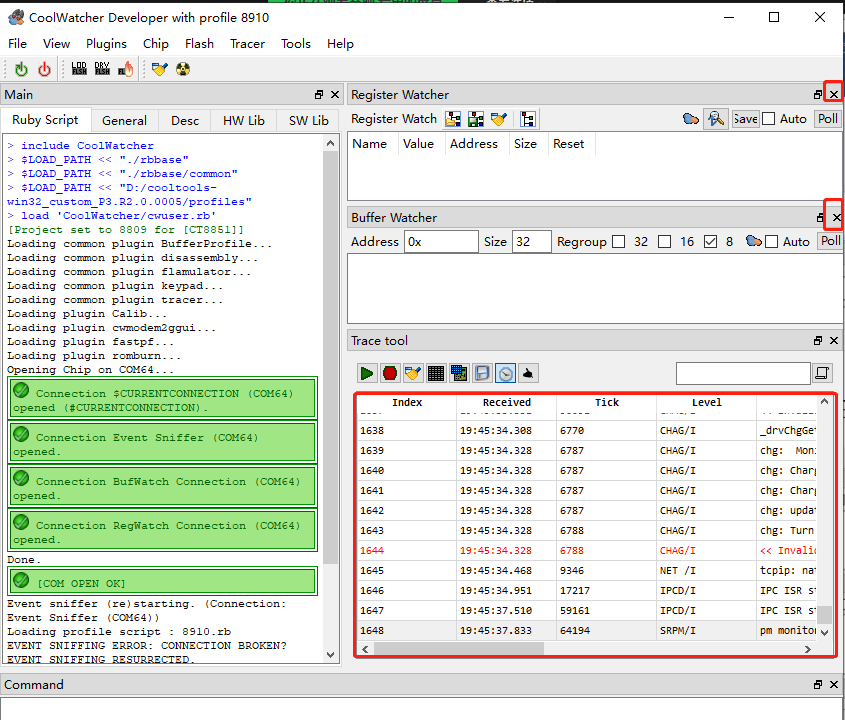
当发生dump时,log输出界面会打印关键字“CP PANIC!”,然后开始保存dump信息(此时可见许多以task开头的日志)

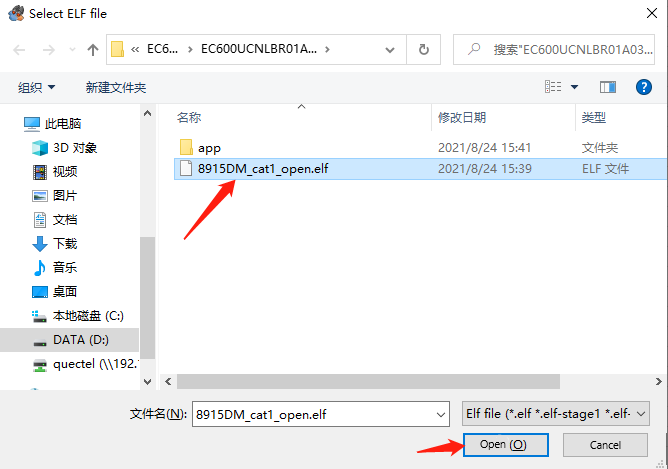
当这些以Task开头的日志停止打印时,说明dump信息准备完毕。此时在Tools下拉框选择Blue Screen dump,选择对应版本的elf文件(一般不随版本输出,有调试需求时移远提供)和输出路径。选择完毕后点击start。
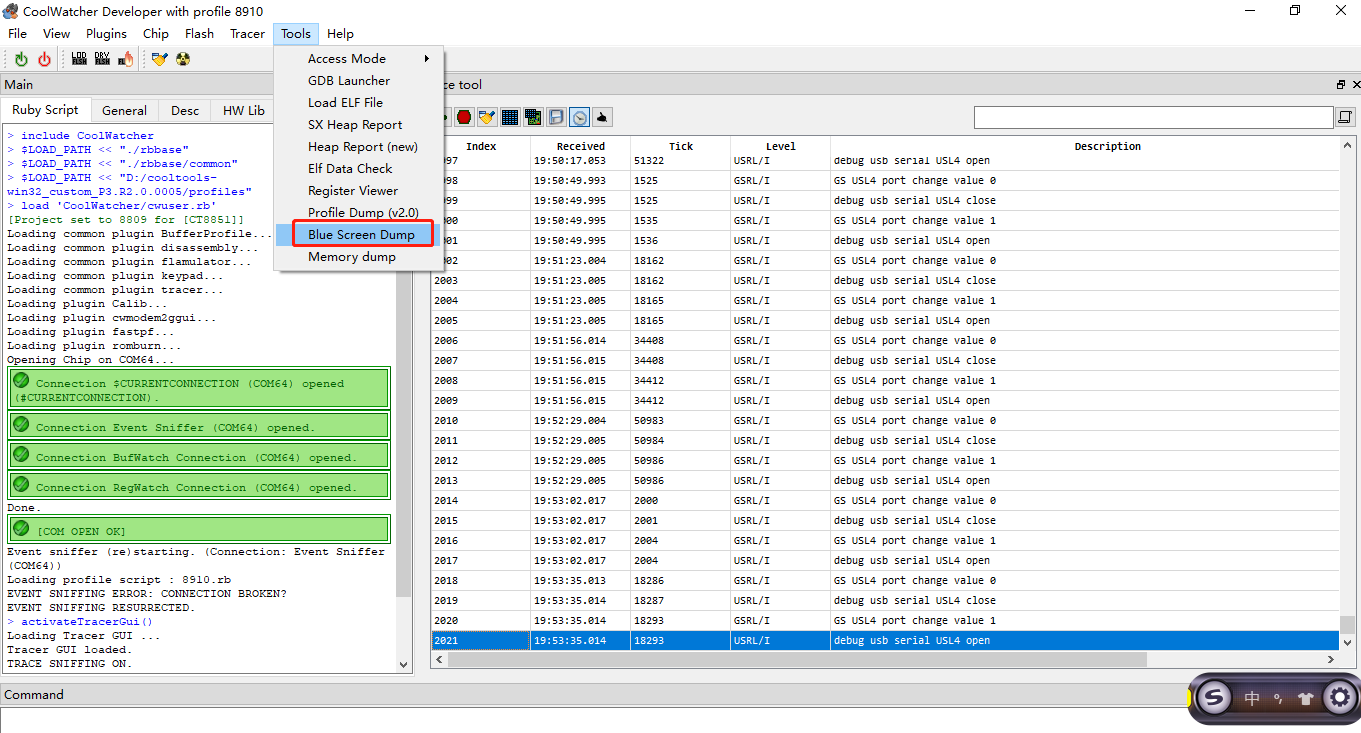

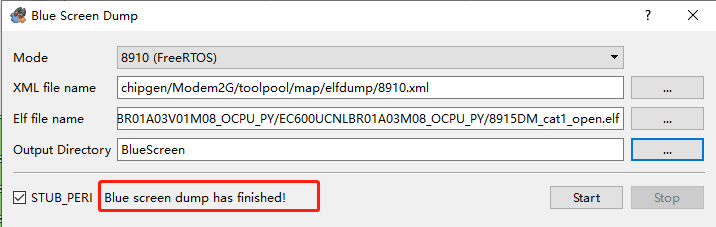
若出现以下界面,则说明dump已经抓取成功,
以下是输出的dump文件,请打包发送给移远分析。
ECX00G系列模组
ECX00G产生dump时,日志口也会打印CP PANIC相关字样,这时,我们需要断开日志工具,使用dtools来抓取dump信息。
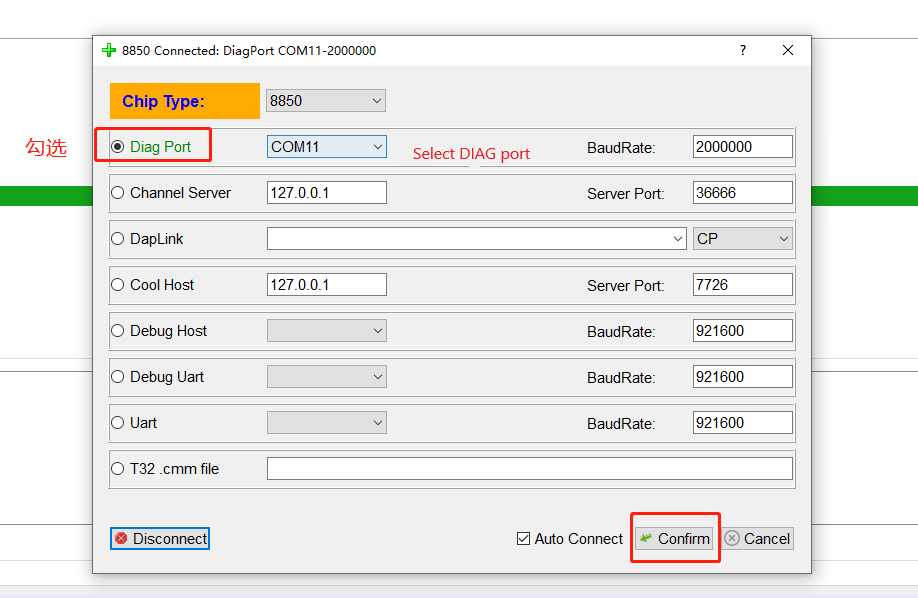
点击dtools左上角的图标,打开配置菜单,选择DIAG口,连接Quectel USB DIAG Port。
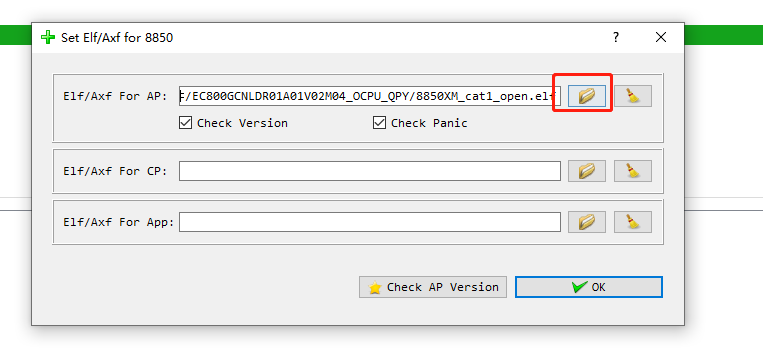
端口连接后,点击右侧的ELF图标,选择对应版本的elf调试文件(一般不随版本输出,有调试需求时移远提供)。


DIAG口和ELF均配置完成后,选择Blue screen dump,此处dump Folder即为dump文件输出路径。点击start开始抓取dump

抓取进度条达到100%时,dump日志抓取成功,打包提供给移远分析

ECX00N/ECX00M/ECX00A系列模组
以上平台进入dump模式后,会重新枚举USB口为Quectel USB Dump Debug Port,如下图:
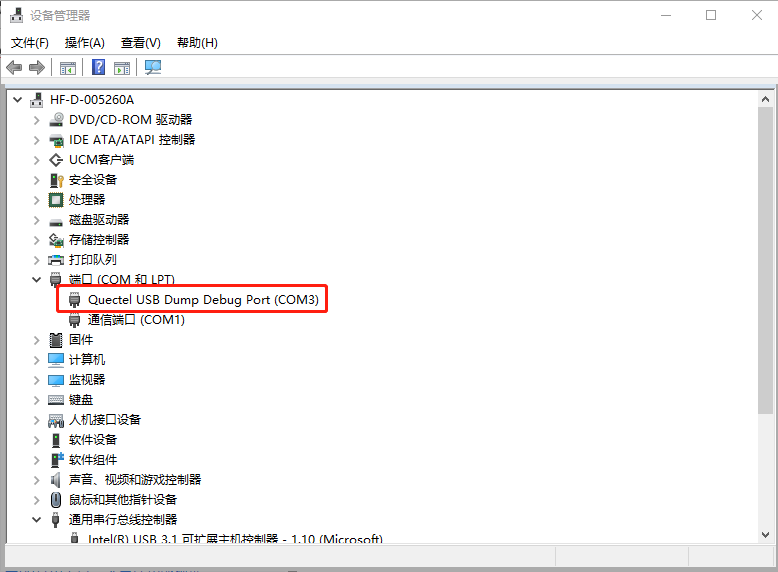
此时我们可以用catlog中的Ymodem工具来抓取Dump信息。Catlog启动后选择“离线解析日志”,进入如下界面,选择Modules->YmodemDump
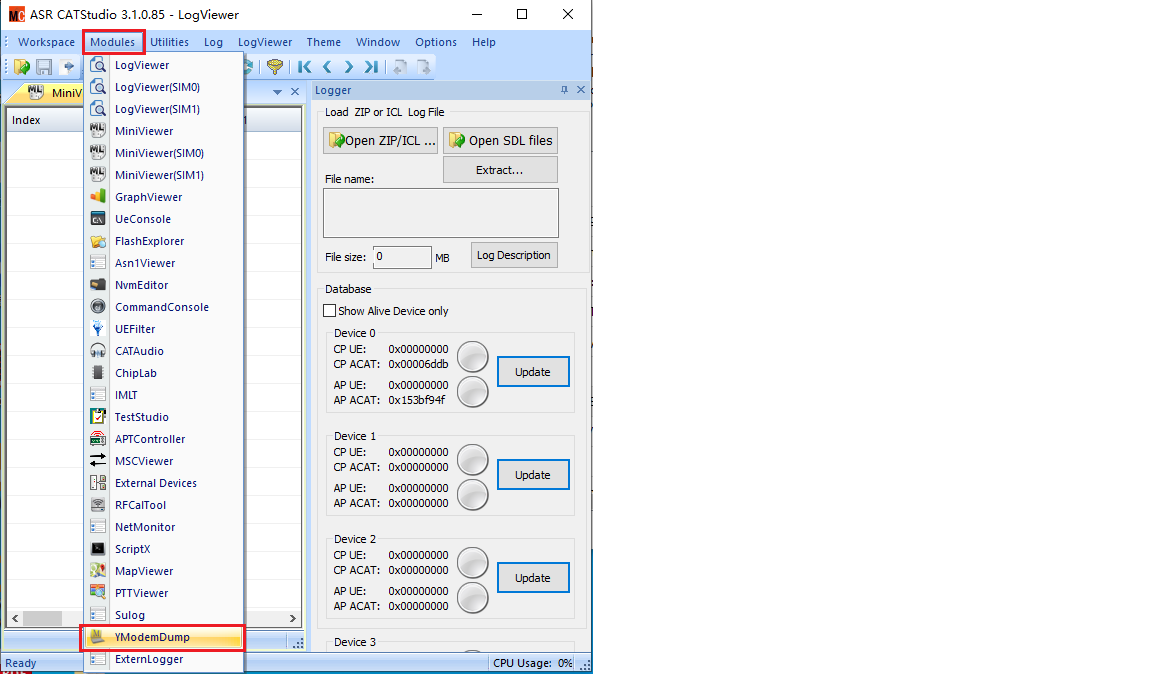
进入如下界面,port选择Quectel USB Dump Debug Port,波特率115200,点击open连接。
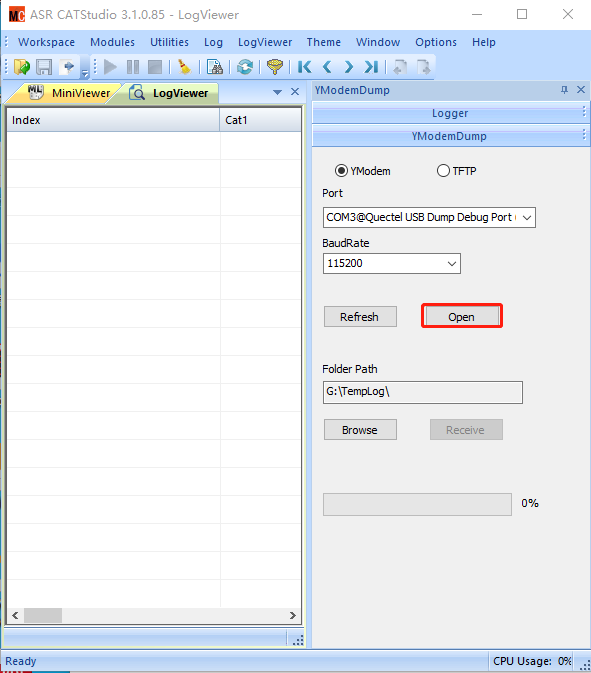
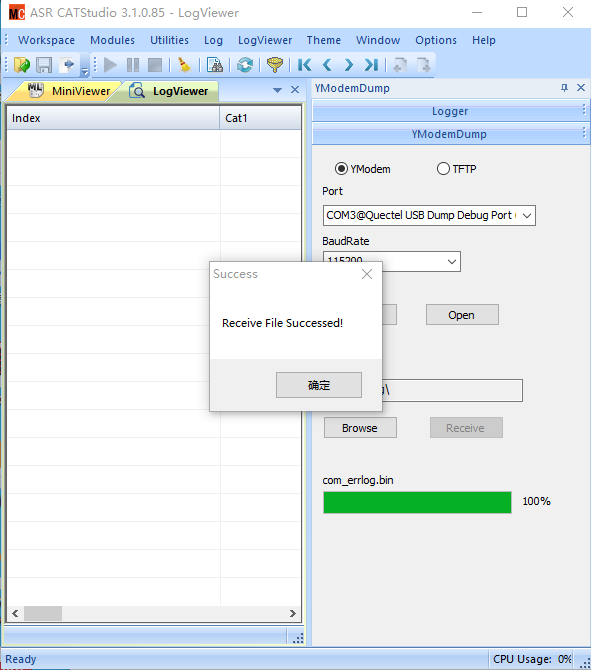
点击Folder Path下方的Browse,选择dump文件输出位置。然后点击Recieve开始抓取dump信息。
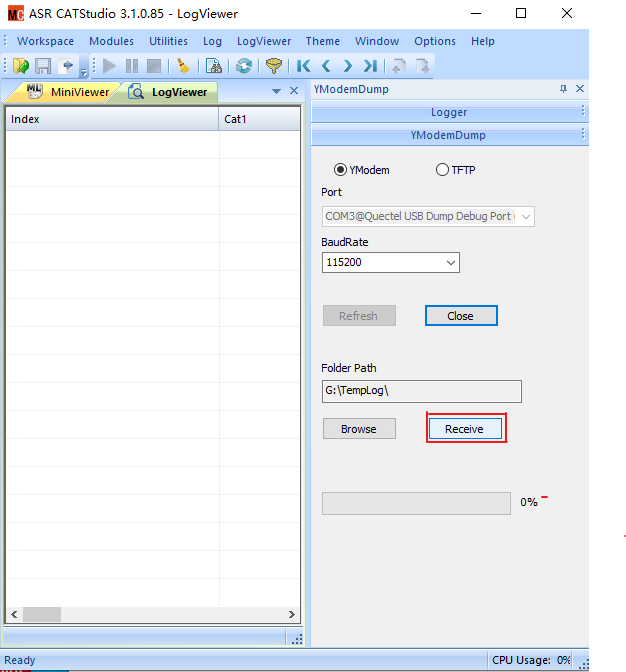
出现如下界面时,dump信息抓取成功,可以打包给移远进行分析。
ECX00E系列模组
该系列模组无需手动执行dump抓取,正常连接日志工具EPAT,出现dump时日志工具会自动进行抓取。注意工具需要匹配mdb信息(一般不随版本输出,有调试需求时移远提供)。

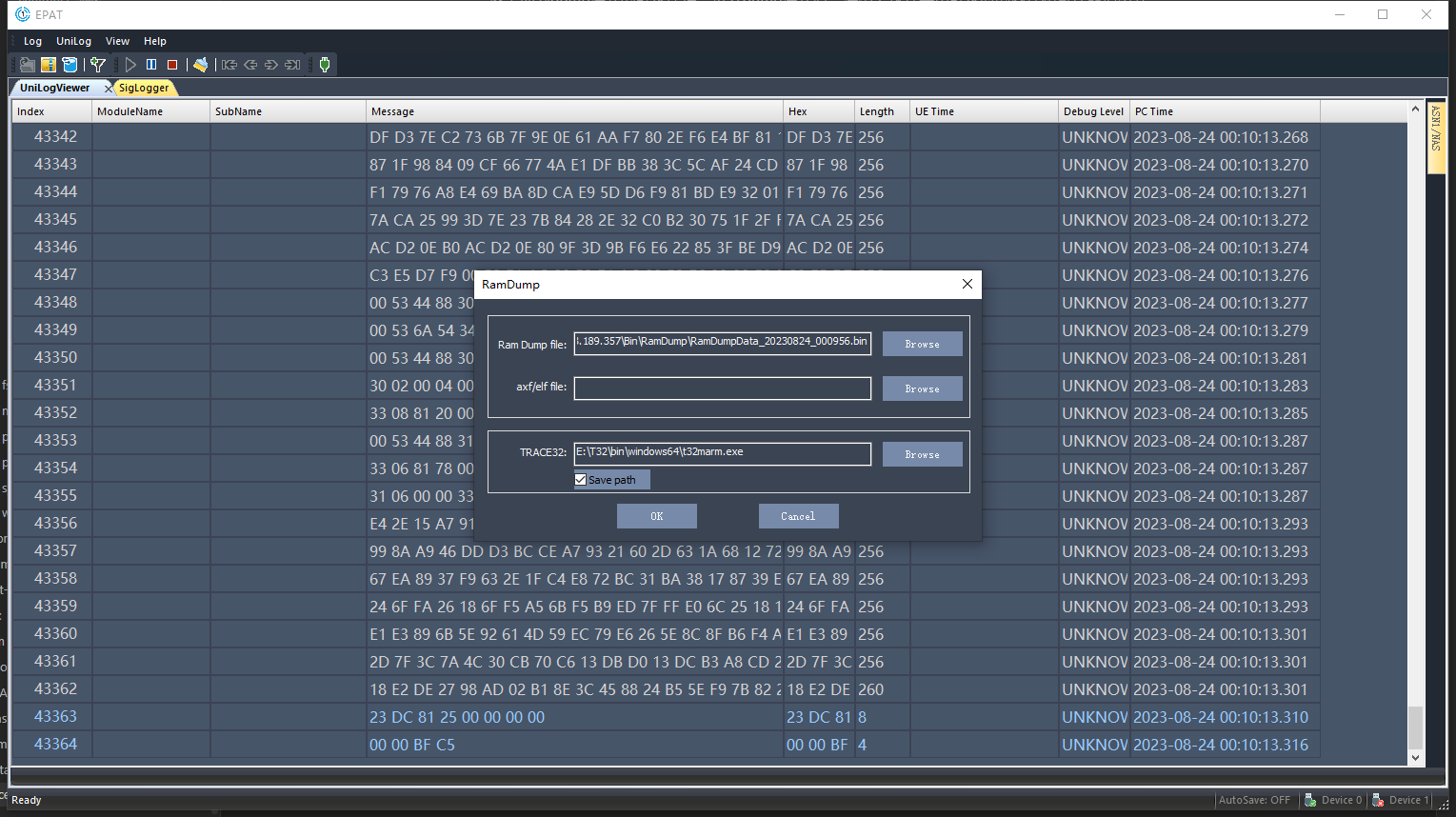
出现dump时,日志工具会自动进行抓取,出现以下界面时,代表已经抓到了dump。
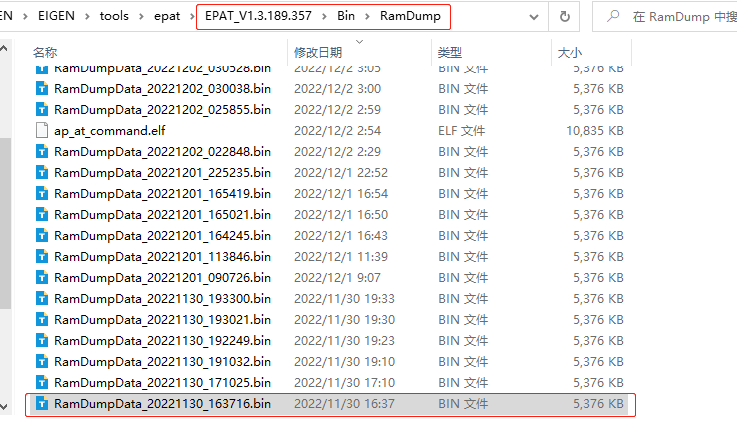
以上的对话框我们可以直接关闭,dump信息此时已经保存在EPAT工具根目录的Ramdump文件夹下,只有一个文件,其命名规则为RamDumpData + 时间戳,根据时间戳选择dump文件,提供给移远分析。
BG95/BG600L系列模组
该系列模组进入Dump模式后也会重新枚举USB,枚举的口为Quectel USB DM Port。我们使用QPST工具来抓取Dump信息。
打开QPST Configuration,点击Add New Port,连接DM口,连接后会自动抓取dump信息并保存在QPST根目录的Sahara目录下。
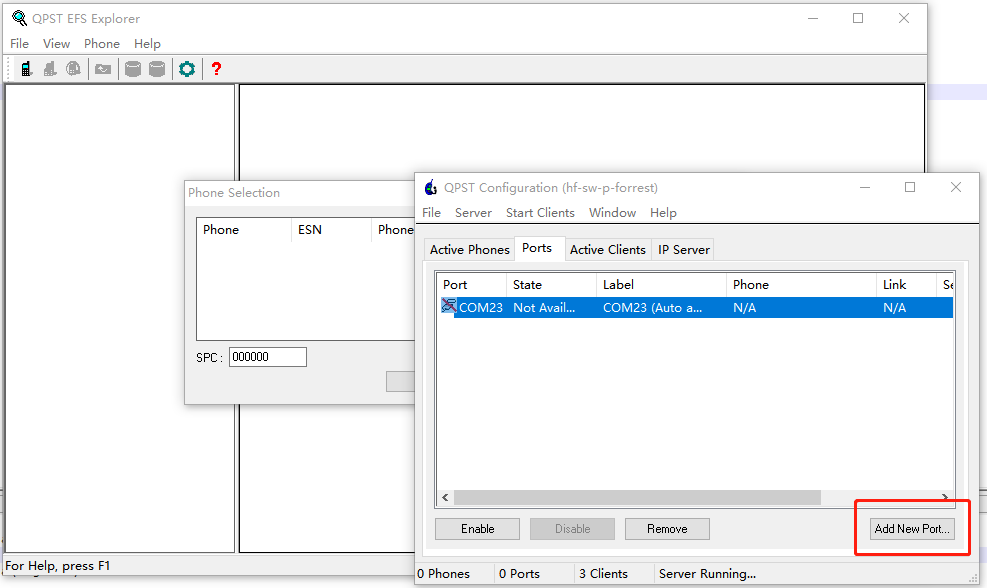
可通过此方式跳转到dump信息保存位置,将dump信息发送给移远分析。
dump时LOG分析
Quecpython模组在进入dump模式时,会从LOG中输出一些信息,例如:dump时的寄存器地址、异常类型、异常产生时正在执行的线程等,如果是assert触发的异常,还会输出对应的调试信息。
各平台log的抓取方式:
对LOG信息的分析一般可从以下几个点入手:
程序寄存器(PC)地址: 该地址对应了异常现场程序寄存器的内容,它负责存储当前正在执行的指令地址。通过该寄存器内的地址,可在固件的map文件内匹配到触发异常时正在执行的函数,从而帮助定位代码中产生异常的位置。
ASSERT调试信息: 一般来说,assert针对的是预想中不应存在的情况。一般在执行某些逻辑前会使用assert进行检查,查看当前运行情况是否在预期内。assert的打印信息一般都会直接输出直接导致异常的原因和位置,有助于判断异常的类型和产生位置。
常见的assert打印和对应信息
WDT timer expired: 在ECX00E的log中会出现,说明模组内置看门狗超时。
Memory allocated failed: 大部分型号的log中都适配了类似的打印,说明申请内存失败,一般是heap不足或过于碎片化导致。
stack overflow: 大部分型号的log中都适配类似打印,说明发生了栈溢出。
illegal poolRef/pMemBlk/pBufHdr: 在ECX00N/M的log中会出现,均系内存结构被破坏,说明发生内存踩踏
看门狗喂狗日志: ECX00U/X00G可以通过计算最后一次喂狗到进入dump的时间间隔,判定是否为模组看门狗引发的异常。以ECX00U为例,当模组配置为dump模式时,该系列模组对内置看门狗进行喂狗时会输出内容为sys feed wdt的日志信息。对比异常现场和最后一次喂狗的时间戳,若时间差超过内置看门狗的狗咬时间(目前设定为30S),则需要考虑异常原因为看门狗超时。
dump 信息分析
dump信息本质上是异常现场模组信息的拷贝,一般包括CPU的寄存器信息、内存信息等。这些信息通过与对应固件版本的调试信息匹配,可以解析出异常出现时的运行状态,包括异常时线程运行状态、栈调用关系、内存用量、信号量等等,这些信息可以分析出dump的原因。
dump的分析一般由移远完成,出现log无法分析原因的dump时,用户可以抓取dump并提供以下信息,由移远对dump进行分析:
场景: 需要结合场景和栈调用关系,分析dump时的运行逻辑。
步骤: 提供复现步骤,以便进行复现和验证。
发生概率: 评估影响范围以及复现条件。
软件版本: 确认发生异常的软件版本,提取对应版本的ELF调试文件。
DUMP文件: 抓取到的dump文件,与对应elf可解析出异常现场。
LOG文件: 条件允许的情况下,尽量抓取LOG(ECX00N/M/A USB和DEBUG uart会同时输出LOG,尽量都抓取),方便技术人员分析。
常见dump场景和解决方案
看门狗超时
Quecpython模组一般内置有看门狗,用以监控系统的运行情况。其喂狗动作一般由一个优先级相对较低的线程来执行。当CPU长期被高优先级的线程抢占时,喂狗线程就会得不到调度。一旦无法喂狗的时间超过了内置看门狗的触发时间阈值(一般为30S),就会触发狗咬,使模组进入dump模式或者复位。
在实际业务中,一般有三种情况会引发看门狗超时:
其一,业务中出现了死循环,且死循环的循环体中缺乏有效的阻塞或者SLEEP。此时,死循环所在的线程会一直占用CPU且无法切出,导致喂狗线程得不到调度,最终触发看门狗超时。
其二,业务中优先级较高的线程抢占了CPU,且执行时间较长。这种情况也会导致喂狗线程得不到调度,最终触发看门狗超时。
其三,对互斥锁使用不当,某处的互斥锁未释放,导致后续逻辑中获取不到互斥锁,产生死锁。
现象:模组日志信息内,有看门狗超时相关信息。或日志中最后一次喂狗到异常现场的时间已经超过看门狗阈值(ECX00U和X00M目前需要如此进行计算,阈值为30S)
解决方案:
1.尽量排除业务中可能的死循环逻辑。
2.在业务中设置合理的阻塞或者sleep,确保低优先级任务能得到正常调度。
3.针对必须使用的循环可增加安全措施。如在循环体中增加循环计数器,即使进入了死循环,也可以在循环达到一定次数时跳出。
4.检查互斥锁,保证其使用一定是成对的。删除拿锁的线程并不会释放其已经持有的互斥锁,这种操作会导致与之互斥的线程无法运行,务必在删除线程前释放其持有的互斥锁。
以下举例说明,首先来看反例
import utime
def Business_code_example():
while(1):
print("It will running to dump")
#Business code here
if __name__ == "__main__":
Business_code_example()
在该例子中,存放有业务函数的循环会一直运行,且没有任何阻塞。在模组上运行该例,会在一段时间后dump。
该例修改如下
import utime
def Business_code_example():
while(1):
print("It will running to dump")
utime.sleep(1)
#Business code here
if __name__ == "__main__":
Business_code_example()
运行该例,不会再产生dump。因为业务代码sleep时,其它任务能得到调度,保证了看门狗能正常喂狗。
栈溢出
Quecpython创建子线程时,仍会从底层的堆内存中申请线程栈空间。如果申请的栈空间过小,不足以存储线程的私有数据时,就会产生栈溢出,即线程私有数据被存储到栈之外的空间,可能会造成相邻内存被破坏,这种现象就是内存踩踏。
产生内存踩踏时,较为常见的dump现象主要有两种:
1.触发assert,部分模组配置了对栈空间的监测机制,出现栈溢出时会主动assert,此时在log以及dump信息中能看到assert输出的信息,一般栈溢出触发的assert会打印stack overflow相关的信息。这种情况可以直接确认问题为栈溢出,做出相应处理。
2.未配置对栈空间的监测,或未能监测到栈溢出的情况下,模组可以继续运行。直到CPU取到被破坏的内存时,就会产生Data Abort或者Prefetch Abort类型的异常。这种异常需要提供dump信息给移远分析才能确认。
解决方案:
在业务中创建子线程时,对其需要的栈大小做出估算(需要计入线程的参数、返回值、局部变量的大小,可以不必太精确),并分配合适大小。若产生栈溢出时,可以使用_thread.stack_size接口来配置更大的栈空间。
以下举例说明:
import _thread
import utime
def th_func1():
while True:
print("Bussiness code running")
#bussiness code here
utime.sleep(1)
if __name__ == '__main__':
stack_size_old = _thread.stack_size()#获取当前栈大小
print(stack_size_old)
_thread.stack_size(stack_size_old + 1024)#如果在当前栈大小下存在栈溢出,可参照此方法适当增加栈大小
thread_id = _thread.start_new_thread(th_func1, ())
中断处理时间过长
中断服务(ISR)拥有比所有线程更高的优先级,并会打断线程运行,若CPU被ISR占用过长时间(ISR内代码运行时间过长,或短时间内触发大量中断,导致频繁进入ISR环境。)会导致RTOS运行异常乃至触发看门狗。
中断处理时间过长的表现一般有两种:
其一,此时日志内有大量中断相关的打印,最后导致看门狗超时
其二,协议栈内数据无法处理,最终产生溢出触发assert
解决方案:
硬件设计方面:妥善配置中断相关电路,做好消抖,避免短时间内多次触发硬件中断的场景
软件设计方面:在中断内避免使用阻塞和耗时操作(典型模式是ISR中发信号到某一线程中,由线程执行实际业务,目前python侧的中断回调机制已经配置了类似处理,可以无需关注)。
非法指针/空指针
由于Quecpython的GC回收机制,局部变量会在未引用时可以被回收。这些局部变量被回收后,如果再次被引用,就会有引入非法指针或空指针的风险。此时如果其数据已经被擦除或覆盖,就会产生Data Abort或者Prefetch Abort类型的异常。
这种问题的现象比较固定,即使用GC回收(无论手动回收还是自动回收)后,出现Data Abort或者Prefetch Abort。这种异常需要提供dump信息给移远分析才能确认。
解决方案:
局部变量在其生命周期之外,随时有被回收的风险。所以,并非时刻都保持被引用,但又期望能进行持久化存储的对象,要配置为全局变量。
常见问题
如何判断是否为异常重启
通过开关机原因可以获取,例如:
from misc import Power
Power.powerOnReason()#返回值为9时,代表发生了异常重启
未设置dump模式程序卡住/设置dump模式程序卡住但是不进dump状态
未将模组配置为dump模式,但程序卡住;或是配置dump模式后程序卡住,但并未进入dump状态。这种情况大部分时候都未产生异常,而是业务运行逻辑出现异常。
调试方法:
1.在业务中增加打印信息,确认业务运行逻辑。
2.主动触发dump, 通过dump信息解析出阻塞时的运行现场
如何主动触发 dump
使用主串口或Quectel USB AT Port发送如下命令:
AT+QDBGCFG="system/abort"
ECX00MLC、LF、CC未适配以上命令,可发送以下命令达到同样效果:
AT+LOG = 14,0
如何分析设置dump模式还会重启
1.设置dump模式还会重启,开机原因指向Dump重启:一般是dump模式未正确配置,重新配置后再次尝试
2.设置dump模式还会重启,开机原因指向RESET重启:一般分两种情况。其一,触发了软重启,需要排查业务逻辑中是否有软重启。其二,reset引脚被触发,挂测RESET引脚波形,查看是否有外部因素触发了硬件reset。
3.设置dump模式还会重启,开机原因指向powerkey启动:只在配置上电自动开机的设备上出现,一般是触发关机后,模组又被powerkey启动。这种情况需要如下三点排查:其一,是否调用了关机接口。其二,挂测VBAT电压波形,查看是否有电压跌落导致模组关机。其三,挂测powerkey引脚,查看其电平是否有波动,形成下降沿,触发关机。
dump抓取过程中报错
一般有两种原因:
1.Dump工具导入的ELF与模组内的固件版本不符,请确认版本并更换ELF。
2.严重的栈破坏,导致dump信息保存异常,这种情况联系移远处理。